
多状态约束卡尔曼滤波器(MSCKF),作为基于滤波架构的视觉惯性里程计(VIO)中应用最广泛的方案,其观测方程中显示存在的特征点三维位置,会带来特征点位置的线性化误差和观测信息的延时更新问题,从而影响VIO的定位精度。受武元新教授团队提出的纯位姿(Pose-Only)表示形式的启发,我们提出了基于纯位姿表示的滤波架构VIO(PO-KF),用纯位姿形式表示特征点位置,显式地将特征点位置从观测方程中移除,有效解决了MSCKF中特征点线性化误差和延时更新的问题。实测结果表明,PO-KF在保持滤波架构计算量低、实时性好优势的同时,展现出显著改善的定位精度和鲁棒性。定位误差相对MSCKF减小了近50%,精度与基于图优化的VIO方案相当。
基于MSCKF的VIO的视觉观测方程如下所示。虽然MSCKF的零空间投影使得状态更新时与特征点位置无关,但是观测方程的构建依然显式地依赖特征点位置,并受特征点位置的线性化误差影响。此外,MSCKF为了得到最准确的特征点位置,只在特征点达到最大跟踪长度或跟踪失败时,利用该特征点的观测构建观测方程(即延时更新),使得延时期间系统状态误差自由发散。
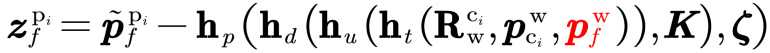
为了解决上述问题,我们引入了纯位姿表示(Pose-Only)方法。
在武元新教授团队提出的纯位姿(Pose-Only [2])的特征表示中,相机位姿和特征点位置被有效解耦,能够显著提升视觉重建问题的优化效率。受此启发,我们将纯位姿的形式引入到滤波架构的VIO系统中,提出了PO-KF [1]。
在纯位姿表示中,用特征点的观测和对应的base帧位姿表示特征点的深度。用纯位姿表示特征点位置后,PO-KF的观测方程中不包含特征点的三维位置,显式地移除了特征点的位置。
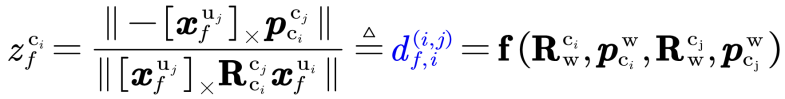
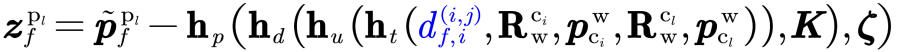
这种显式的移除,使得观测方程不受特征点位置带来的线性化误差的影响。由于PO-KF不直接依赖特征点的三维位置,因此只需要特征点连续跟踪超过三帧,便可构建准确的视觉观测方程进行及时的状态更新。PO-KF的及时观测更新,也使得系统状态误差一直维持在较小的水平,进一步减少线性化误差的影响。

图1 PO-KF与MSCKF的更新策略图
图1 (a) MSCKF更新策略,虚线表示更新时刻,所有观测在最后一帧观测到来时刻(绿色相机)更新系统状态;(b) PO-KF更新策略,黑色虚线对应base帧,第二帧之后所有观测在其对应时刻更新系统状态
PO-KF与MSCKF的综合对比如表1所示。
表1 PO-KF与MSCKF对比

图2 展示了机器人数据集其中一组的测试轨迹。从轨迹平滑性上看,PO-KF相比于基于MSCKF的OpenVINS有显著的改善,主要得益于特征点的及时更新;从终点对齐和轨迹一致性来看,PO-KF相比于所有对比方法表现出更优的定位精度。

图2 一组机器人数据的定位轨迹
表2展示了PO-KF和对比方法在机器人数据集上的绝对定位精度。PO-KF的绝对位姿精度相比于基于MSCKF的OpenVINS有显著的改善;PO-KF位姿精度也优于基于图优化的VINS-Mono,其中位置精度的优势更明显;PO-KF的位姿精度与基于图优化的IC-VINS精度相当。
表2 机器人数据集绝对位姿误差[deg/m] (加粗表示在四种方法中定位误差最小)
![表2 机器人数据集绝对位姿误差[deg/m] (加粗表示在四种方法中定位误差最小)](/ueditor/jsp/upload/image/20251007/1759824328128090046.png "表2 机器人数据集绝对位姿误差[deg/m] (加粗表示在四种方法中定位误差最小)")
图3和图4展示了在机器人数据集上的不同轨迹长度下的相对位置和相对姿态精度。除了10m的相对姿态精度略差于VINS-Mono,PO-KF在其他轨迹长度的相对位置和姿态精度均优于对比方法,包括基于图优化和基于滤波的VIO方案。

图3 机器人数据集相对位置精度

图4 机器人数据集相对姿态精度
更详细的算法方案和测试结果可参考我们的论文。PO-KF论文已被SCI 一区TOP期刊IEEE Internet of Things Journal接收。
参考论文:
[1] L. Wang, H. Tang, T. Zhang, Y. Wang, Q. Zhang, and X. Niu, “PO-KF: A Pose-Only Representation-based Kalman Filter for Visual Inertial Odometry,” IEEE Internet of Things Journal, pp. 1–1, 2025, doi:10.1109/JIOT.2025.3526811.
[2] Q. Cai, L. Zhang, Y. Wu, W. Yu, and D. Hu, “A Pose-Only Solution to Visual Reconstruction and Navigation,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 45, no. 1, pp. 73–86, Jan. 2023, doi: 10.1109/TPAMI.2021.3139681.
[3] H. Tang, X. Niu, T. Zhang, L. Wang, G. Wang, and J. Liu, “PO-VINS: An Efficient Pose-Only LiDAR-Enhanced Visual-Inertial State Estimator”, [Online]. Available: https://arxiv.org/abs/2305.12644
版权所有:武汉大学多源智能导航实验室(微信公众号:i2Nav) 当前访问量: 技术支持:武汉楚玖科技有限公司